Scale Robot Reinforcement Learning with NVIDIA Isaac Lab on Amazon SageMaker AI
Quick Summary
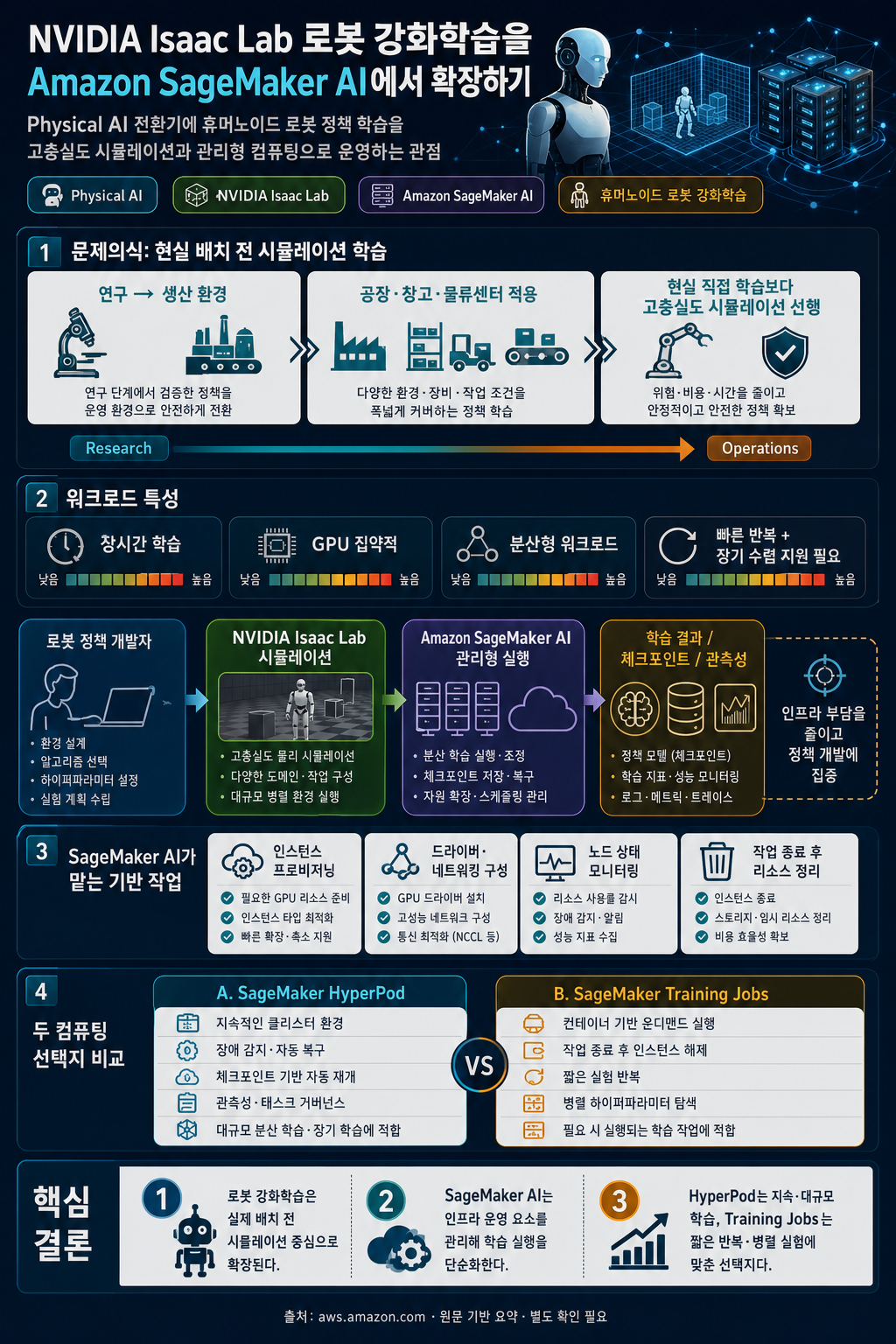
이 글은 NVIDIA Isaac Lab 기반 휴머노이드 로봇 강화학습을 Amazon SageMaker AI에서 실행하는 방식과, HyperPod와 Training Jobs라는 두 컴퓨팅 선택지가 각각 어떤 학습 단계에 적합한지 설명한다.

🖼️ 인포그래픽
🖼️ 4컷 인포그래픽
💡 한 줄 요약
이 글은 NVIDIA Isaac Lab 기반 휴머노이드 로봇 강화학습을 Amazon SageMaker AI에서 실행하는 방식과, HyperPod와 Training Jobs라는 두 컴퓨팅 선택지가 각각 어떤 학습 단계에 적합한지 설명한다.
📌 핵심 요약
- Physical AI가 연구 단계를 넘어 공장, 창고, 물류센터 같은 실제 운영 환경으로 이동하면서, 로봇은 현실에서 직접 학습하기보다 고충실도 시뮬레이션에서 먼저 훈련되는 흐름이 강해지고 있다.
- 복잡한 로봇 행동을 위한 강화학습은 장시간·GPU 집약적·분산형 워크로드가 되기 쉬우므로, 연구 단계의 빠른 반복과 수렴까지 이어지는 장기 학습을 모두 지원하는 관리형 컴퓨팅이 중요하다.
- Amazon SageMaker AI는 인스턴스 프로비저닝, 드라이버와 네트워킹 구성, 노드 상태 모니터링, 작업 종료 후 리소스 정리 등을 맡아 로봇 정책 개발자가 인프라 관리보다 학습 코드와 정책 개선에 집중하게 한다.
- SageMaker HyperPod는 지속적인 클러스터 환경, 장애 감지와 자동 복구, 체크포인트 기반 자동 재개, 관측성과 태스크 거버넌스를 제공해 대규모 분산 학습과 장기 실행 작업에 적합하다.
- SageMaker Training Jobs는 컨테이너 기반 학습 작업을 온디맨드로 실행하고 종료 후 인스턴스를 해제하므로, 짧은 실험 반복이나 병렬 하이퍼파라미터 탐색처럼 유휴 컴퓨팅 비용을 줄여야 하는 단계에 적합하다.
🧩 주요 포인트
- Physical AI가 연구 단계를 넘어 공장, 창고, 물류센터 같은 실제 운영 환경으로 이동하면서, 로봇은 현실에서 직접 학습하기보다 고충실도 시뮬레이션에서 먼저 훈련되는 흐름이 강해지고 있다.
- 복잡한 로봇 행동을 위한 강화학습은 장시간·GPU 집약적·분산형 워크로드가 되기 쉬우므로, 연구 단계의 빠른 반복과 수렴까지 이어지는 장기 학습을 모두 지원하는 관리형 컴퓨팅이 중요하다.
- Amazon SageMaker AI는 인스턴스 프로비저닝, 드라이버와 네트워킹 구성, 노드 상태 모니터링, 작업 종료 후 리소스 정리 등을 맡아 로봇 정책 개발자가 인프라 관리보다 학습 코드와 정책 개선에 집중하게 한다.
- SageMaker HyperPod는 지속적인 클러스터 환경, 장애 감지와 자동 복구, 체크포인트 기반 자동 재개, 관측성과 태스크 거버넌스를 제공해 대규모 분산 학습과 장기 실행 작업에 적합하다.
- SageMaker Training Jobs는 컨테이너 기반 학습 작업을 온디맨드로 실행하고 종료 후 인스턴스를 해제하므로, 짧은 실험 반복이나 병렬 하이퍼파라미터 탐색처럼 유휴 컴퓨팅 비용을 줄여야 하는 단계에 적합하다.
🧠 상세 정리
1. Physical AI 학습이 시뮬레이션 중심으로 이동하는 배경
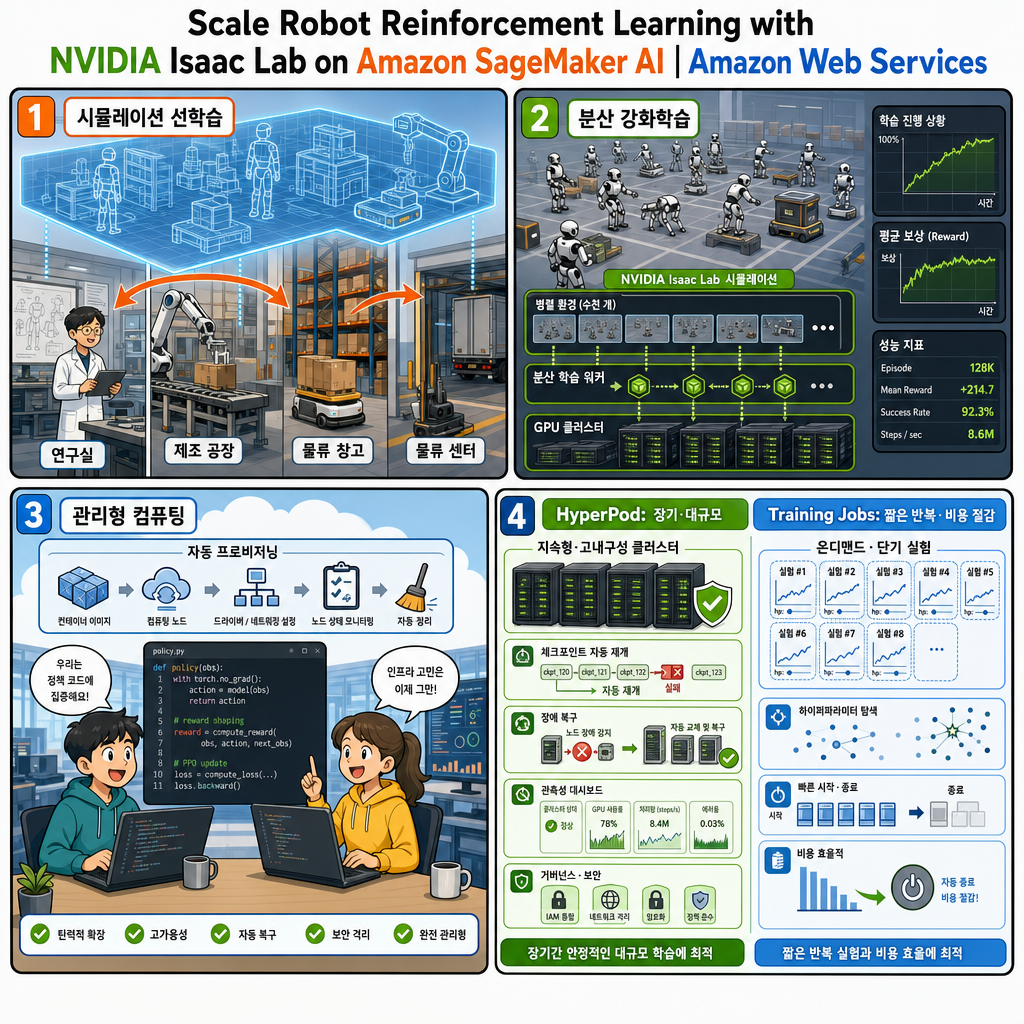
글은 Physical AI가 연구에서 생산 환경으로 옮겨가고 있다는 문제의식에서 출발한다. 로봇을 실제 공장, 창고, 물류센터에 배치하기 전에 고충실도 시뮬레이션에서 훈련하는 이유는 현실 학습이 느리고 비싸며 안전 문제도 크기 때문이다. GPU 가속 시뮬레이션은 현실에서 몇 달이 걸릴 수 있는 경험 축적을 몇 시간 단위로 압축할 수 있다. 따라서 핵심 병목은 더 이상 단순히 로봇을 어떻게 움직일지의 문제가 아니라, 복잡한 정책 학습을 감당할 계산 자원을 어떻게 안정적으로 확보하고 운영할지의 문제로 이동한다.
2. 로봇 강화학습에서 컴퓨팅 부담이 커지는 이유
복잡한 행동을 학습하는 강화학습은 계산량이 매우 큰 작업으로 제시된다. 예시로 거친 지형에서 휴머노이드가 보행하는 정책을 학습시키는 경우, 단일 노드 학습만으로도 몇 시간에서 며칠까지 이어질 수 있다. 로봇 연구팀은 보상 함수, 관측 공간, 모델 구조를 빠르게 바꾸며 실험해야 하는 동시에, 튜닝된 설정을 장시간 실행해 수렴시키는 생산급 학습도 수행해야 한다. 이 두 요구를 모두 만족하려면 단순 GPU 서버 확보를 넘어 장애, 분산 실행, 비용, 재현성까지 다루는 학습 운영 체계가 필요하다.
3. SageMaker AI가 제공하는 관리형 학습 인프라의 역할
Amazon SageMaker AI는 머신러닝 학습을 위해 필요한 인프라 관리 부담을 줄이는 서비스로 설명된다. 인스턴스 프로비저닝, 드라이버와 네트워킹 구성, 노드 상태 모니터링, 작업 완료 후 리소스 종료 같은 과정을 서비스가 처리한다. 이를 통해 엔지니어링 역량은 기반 인프라를 돌보는 일보다 로봇 정책 자체를 개발하고 개선하는 데 집중될 수 있다. 특히 로봇 정책 강화학습은 실행 시간이 길고 GPU를 많이 사용하며 여러 노드로 분산되는 경우가 많아, 이런 관리형 기능의 효과가 더 커진다.
4. HyperPod가 장기·분산 학습에 맞는 이유
SageMaker HyperPod는 대규모 분산 학습과 추론을 위해 설계된 관리형 인프라로 소개된다. 글에서 강조하는 핵심은 회복탄력성이다. 여러 노드가 참여하는 강화학습에서는 하드웨어 장애가 발생하면 학습 진행분을 잃고, 장애를 감지하고 노드를 교체한 뒤 체크포인트에서 재시작하는 데 시간이 든다. HyperPod는 각 노드에 상태 모니터링 에이전트를 실행해 기본 및 심층 상태 점검을 수행하고, 문제가 감지되면 인스턴스를 자동으로 재부팅하거나 교체한다. 자동 재개 기능은 교체 노드가 준비되면 마지막 체크포인트부터 학습을 다시 시작하게 해 수동 개입을 줄인다.
5. HyperPod의 오케스트레이션, 관측성, 거버넌스
HyperPod는 Amazon EKS 또는 Slurm으로 오케스트레이션되며, 클러스터 노드에 직접 접근할 수 있고 실행 사이에도 유지되는 안정적 환경을 제공한다. 관측성 애드온은 클러스터, 노드, 작업 단위의 수백 개 지표를 Amazon Managed Service for Prometheus로 내보내고, Amazon Managed Grafana 대시보드에서 시각화한다. 팀은 별도 메트릭 파이프라인을 구축하지 않아도 GPU 사용률, 메모리 압박, 네트워크 처리량, 작업 수준 성능을 확인할 수 있다. 또한 Kueue 기반 태스크 거버넌스를 통해 네임스페이스 단위 큐, 할당량, 우선순위, 선점 정책을 정의하고 GPU 전체나 MIG 파티션 단위까지 세밀하게 자원을 배분할 수 있다.
6. Training Jobs가 실험 반복과 병렬 탐색에 적합한 이유
SageMaker Training Jobs는 장기 유지되는 컴퓨팅 클러스터 없이 컨테이너화된 학습 워크로드를 실행하는 온디맨드 방식으로 설명된다. 각 작업은 GPU 인스턴스를 프로비저닝하고, Amazon ECR에서 컨테이너를 가져오며, 학습 스크립트를 실행하고, 산출물을 Amazon S3에 업로드한 뒤 인스턴스를 종료한다. 실행 사이에는 유휴 컴퓨팅 비용이 발생하지 않는다. 이 특성은 보상 함수, 관측 공간, 네트워크 아키텍처가 자주 바뀌는 정책 개발의 반복 단계에 잘 맞는다. 또한 여러 짧은 실행을 병렬로 수행한 뒤 리소스를 해제하는 하이퍼파라미터 튜닝 스윕에도 적합하다.
7. Isaac Lab과 Unitree H1 보행 학습 과제
NVIDIA Isaac Lab은 NVIDIA Isaac Sim 위에 구축된 오픈소스 로봇 학습 프레임워크로 소개된다. GPU 병렬 시뮬레이션을 활용해 하나 또는 여러 GPU에서 수천 개의 로봇 인스턴스를 동시에 실행할 수 있으며, 현실에서는 오랜 시간이 걸릴 경험을 시뮬레이션 학습으로 압축한다. 글의 예제 과제는 Isaac-Velocity-Rough-H1-v0로, Unitree H1 휴머노이드가 거친 지형을 걸으며 속도 명령을 추종하도록 학습하는 작업이다. 로봇은 절차적으로 생성된 울퉁불퉁한 표면에서 균형을 유지하기 위해 19개 관절을 조정해야 하며, 학습에는 Isaac Lab이 지원하는 강화학습 프레임워크 중 하나인 skrl을 통한 PPO가 사용된다.
8. 공통 컨테이너와 생성 스크립트로 두 백엔드를 연결하는 구조
제공되는 솔루션은 두 가지 핵심 요소로 구성된다. 첫째는 SageMaker HyperPod와 SageMaker Training Jobs 양쪽에서 같은 학습 코드를 실행하는 단일 Docker 이미지이고, 둘째는 공유 설정 파일을 바탕으로 Kubernetes 매니페스트와 SageMaker 실행 스크립트를 렌더링하는 생성 스크립트다. 두 서비스 선택지는 이미지를 어떻게 시작하느냐만 다르며, HyperPod에서는 Kubernetes PyTorchJob으로 실행되고 Training Jobs에서는 CreateTrainingJob API 호출로 실행된다. H1 보행 학습 코드는 기존 NVIDIA Isaac Lab on AWS 워크숍과 같지만, SageMaker AI로 옮기면서 관리형 클러스터, 통합 장애 복구, 서버리스 학습 작업 실행을 더한다.
9. 학습 이미지, MLflow 추적, 분산 실행 토폴로지
학습 컨테이너 이미지는 nvcr.io/nvidia/isaac-sim:5.1.0을 기반으로 하며, Dockerfile은 Isaac Lab v2.3.2를 클론하고 Isaac Sim에 포함된 Python 환경에 설치한 뒤 torchrun을 실행하기 위한 엔트리포인트 스크립트를 복사한다. 두 백엔드는 동일한 이미지와 동일한 Isaac Lab skrl trainer 실행으로 이어지지만, 컨테이너에 토폴로지를 전달하는 방식이 다르다. HyperPod에서는 Kubeflow Training Operator가 MASTER_ADDR, MASTER_PORT, RANK, WORLD_SIZE를 각 파드에 주입하고, 엔트리포인트가 이를 torchrun에 전달한다. Training Jobs에서는 SageMaker가 호스트 목록을 /opt/ml/input/config/resourceconfig.json에 기록하고, 컨테이너 엔트리포인트가 시작 시 이를 파싱한다. 선택적으로 SageMaker managed MLflow를 사용하면 두 백엔드의 학습 지표를 지속적으로 추적하고 검색할 수 있다.
10. GPU 호환성과 예제 실행 준비
Isaac Sim은 NVIDIA Omniverse와 Omniverse RTX Renderer를 기반으로 하므로 하드웨어 RT Cores가 있는 GPU가 필요하다고 설명된다. 따라서 AWS GPU 인스턴스 중 G 계열은 Isaac Lab 워크로드에 적합하지만, 데이터센터 GPU를 사용하는 P 계열은 호환되지 않는 것으로 정리된다. 글의 예제는 ml.g6.12xlarge를 사용하며, 설정은 config.yaml에서 바꿀 수 있다. ml.g6, ml.g6e, ml.g7e 계열은 8xlarge 이상에서 EFA를 지원해 다중 노드 collective 통신에 유리한 전송 경로를 제공한다. 실행 준비는 저장소를 클론하고, Dockerfile과 설정 템플릿, 생성기, 엔트리포인트 스크립트를 포함한 코드를 바탕으로 이미지를 빌드한 뒤 Amazon ECR에 푸시하는 공통 단계로 시작된다.
🧾 핵심 주장 / 시사점
- 이 글의 핵심은 로봇 강화학습의 성패가 알고리즘만이 아니라 장시간 GPU 분산 학습을 안정적으로 반복·복구·관측할 수 있는 운영 구조에 달려 있다는 점이다.
- HyperPod와 Training Jobs는 경쟁 관계라기보다 학습 수명주기의 서로 다른 구간을 담당한다. 전자는 지속적이고 복원력이 필요한 장기 분산 학습에, 후자는 짧은 실험과 병렬 탐색에 맞춰져 있다.
- 동일한 컨테이너와 학습 코드를 두 실행 환경에서 재사용하도록 설계한 점은 연구 실험에서 생산형 학습으로 넘어갈 때 코드 변경보다 실행 방식과 인프라 정책을 바꾸는 접근을 가능하게 한다.
✅ 액션 아이템
- 원문에서 강조한 핵심 변화와 이해관계자를 기준으로 Scale Robot Reinforcement Learning with NVIDIA Isaac Lab on Amazon SageMaker AI | Amazon Web Services의 영향을 정리한다.
- 다음 의사결정이나 제품/정책 판단에 연결될 수 있는 근거를 원문 문장과 함께 기록한다.
- 기사에서 제시한 수치·사례·제약 조건을 분리해 과장 없이 검토한다.
- 후속 모니터링이 필요한 발표·제품·정책 변화가 있는지 출처 링크를 기준으로 추적한다.
❓ 열린 질문
- How the UK Is Turning Sovereign AI Ambition Into Action With NVIDIA Technologies]]" "209. 이 변화가 실제 사용자나 조직의 선택 기준을 어떻게 바꿀까?
- The Future of AI Learning Environments" "217. 이 근거가 다른 산업이나 지역에서도 동일하게 적용될 수 있을까?
- Google DeepMind is worried about what happens when millions of agents start to interact MIT Technology Review" "[[175. 기사에서 아직 검증되지 않은 전제나 리스크는 무엇일까?
- Businesses are declaring war on AI slop. 후속 발표나 데이터가 나오면 어떤 지표를 먼저 비교해야 할까?





