Evaluate AI agents systematically with Agent-EvalKit
Quick Summary
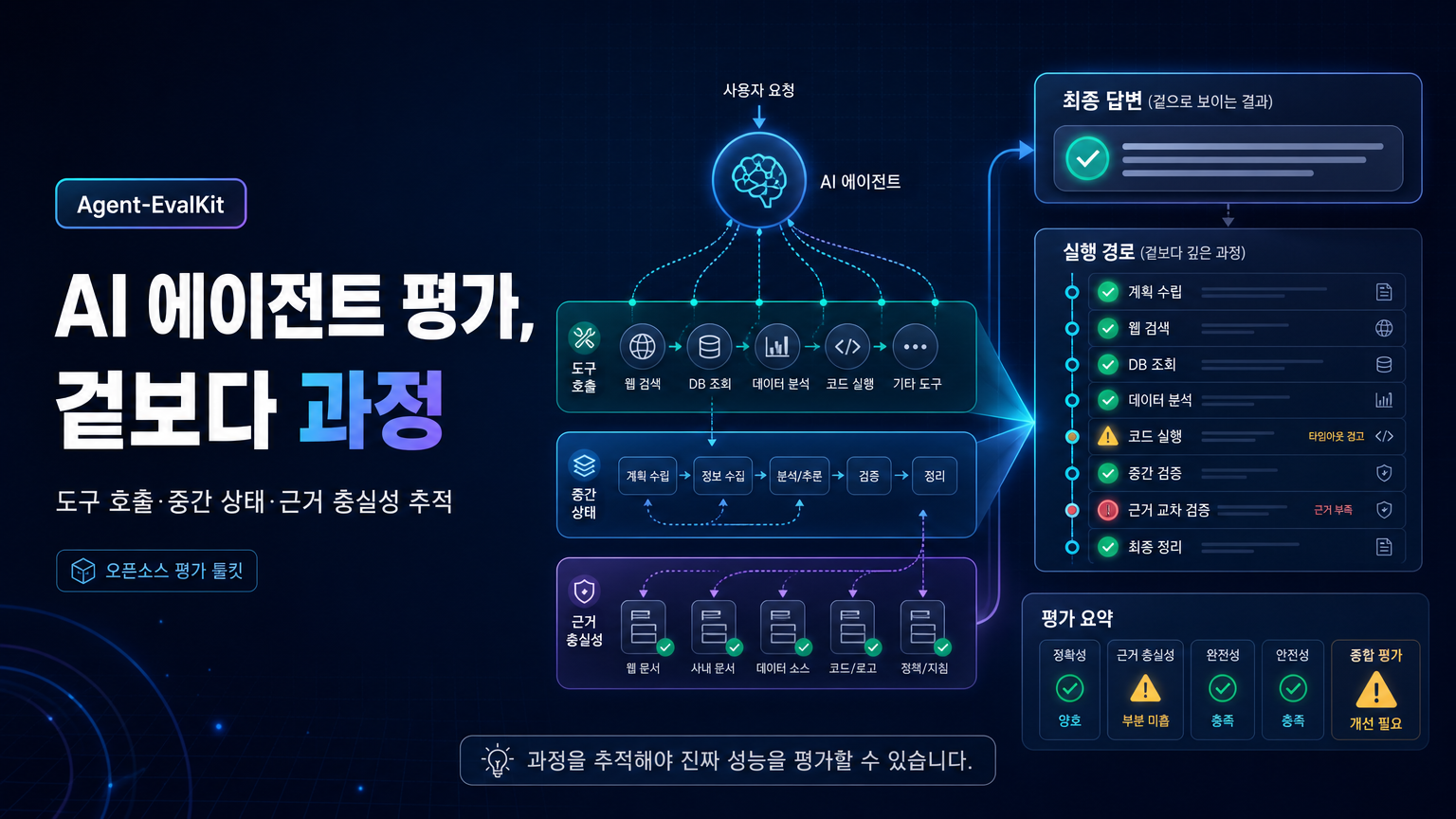
Agent EvalKit은 최종 응답만 보는 평가의 한계를 넘어, AI 에이전트의 도구 호출·중간 상태·근거 충실성까지 추적해 코드 수준 개선으로 연결하는 오픈소스 평가 도구입니다.
🖼️ 인포그래픽

🖼️ 4컷 인포그래픽
💡 한 줄 요약
Agent-EvalKit은 최종 응답만 보는 평가의 한계를 넘어, AI 에이전트의 도구 호출·중간 상태·근거 충실성까지 추적해 코드 수준 개선으로 연결하는 오픈소스 평가 도구입니다.
📌 핵심 요약
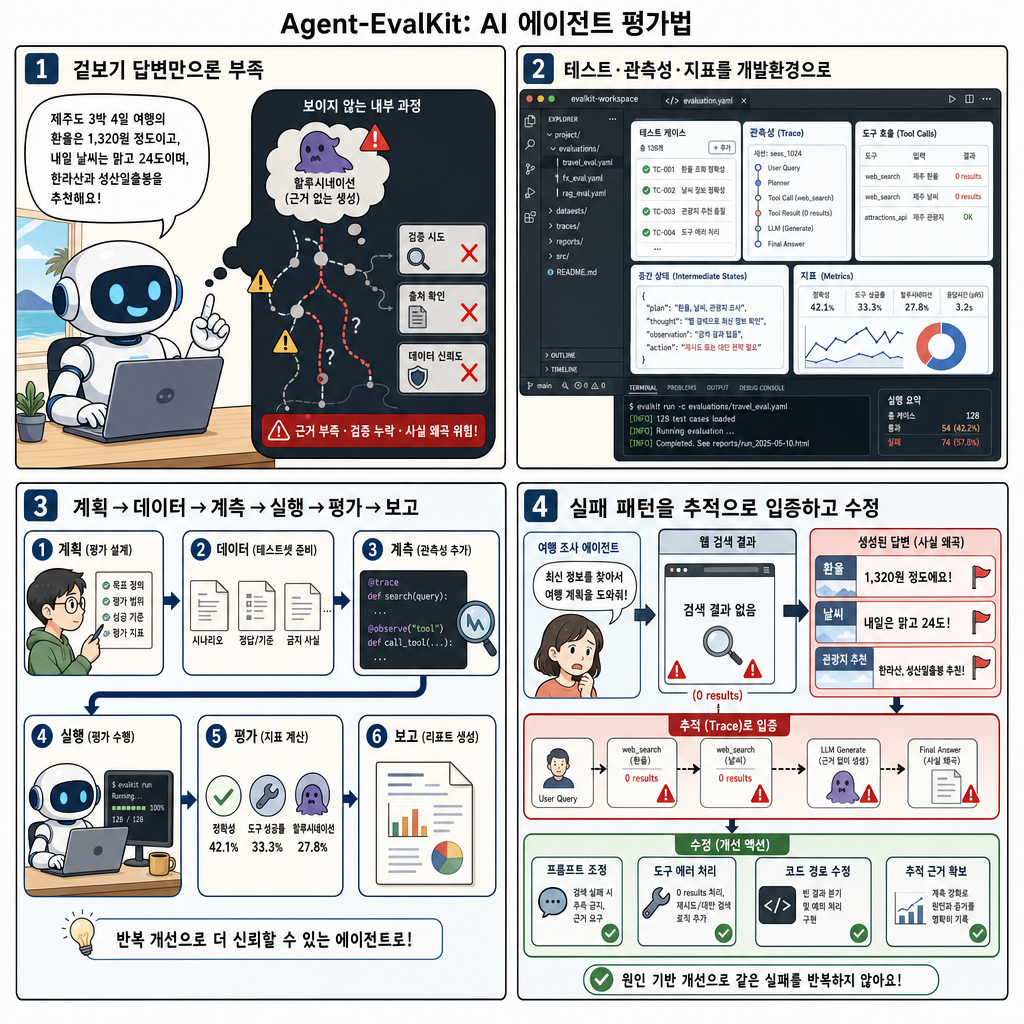
- AI 에이전트는 일반 소프트웨어처럼 최종 출력이 기대와 맞는지만 확인해서는 충분히 평가하기 어렵습니다. 도구를 자율적으로 선택하고 여러 소스에 걸쳐 작업을 순서화하기 때문에, 겉으로는 그럴듯한 답변이어도 내부 실행 경로에서는 환각이나 검증 누락이 발생할 수 있습니다.
- Agent-EvalKit은 이러한 공백을 메우기 위해 테스트 케이스, 도구 호출과 중간 상태를 포착하는 관측성, 근거 충실성·도구 사용·응답 품질을 평가하는 지표를 개발 환경 안으로 가져오는 Apache 2.0 오픈소스 툴킷입니다.
- 이 도구는 Claude Code, Kiro CLI, Kilo Code 같은 AI 코딩 어시스턴트와 통합되어, 자연어 지시를 바탕으로 에이전트 소스 코드를 읽고 평가 계획 수립, 테스트 데이터 생성, 추적 계측, 실행, 평가, 보고서 작성까지 여섯 단계를 수행합니다.
- 예시로 제시된 여행 리서치 에이전트 평가에서는 응답 품질은 높았지만 Faithfulness 점수가 낮게 나왔고, 웹 검색 도구가 빈 결과나 불완전한 결과를 반환할 때 환율·온도·명소 정보를 지어내는 문제가 드러났습니다.
- Agent-EvalKit의 핵심 가치는 단순 점수 대시보드가 아니라, 실패 패턴을 실행 추적과 지표로 입증한 뒤 시스템 프롬프트, 도구 오류 처리, 코드 경로 등 구체적인 수정 지점과 우선순위를 제시한다는 점입니다.
🧩 주요 포인트
- AI 에이전트는 일반 소프트웨어처럼 최종 출력이 기대와 맞는지만 확인해서는 충분히 평가하기 어렵습니다. 도구를 자율적으로 선택하고 여러 소스에 걸쳐 작업을 순서화하기 때문에, 겉으로는 그럴듯한 답변이어도 내부 실행 경로에서는 환각이나 검증 누락이 발생할 수 있습니다.
- Agent-EvalKit은 이러한 공백을 메우기 위해 테스트 케이스, 도구 호출과 중간 상태를 포착하는 관측성, 근거 충실성·도구 사용·응답 품질을 평가하는 지표를 개발 환경 안으로 가져오는 Apache 2.0 오픈소스 툴킷입니다.
- 이 도구는 Claude Code, Kiro CLI, Kilo Code 같은 AI 코딩 어시스턴트와 통합되어, 자연어 지시를 바탕으로 에이전트 소스 코드를 읽고 평가 계획 수립, 테스트 데이터 생성, 추적 계측, 실행, 평가, 보고서 작성까지 여섯 단계를 수행합니다.
- 예시로 제시된 여행 리서치 에이전트 평가에서는 응답 품질은 높았지만 Faithfulness 점수가 낮게 나왔고, 웹 검색 도구가 빈 결과나 불완전한 결과를 반환할 때 환율·온도·명소 정보를 지어내는 문제가 드러났습니다.
- Agent-EvalKit의 핵심 가치는 단순 점수 대시보드가 아니라, 실패 패턴을 실행 추적과 지표로 입증한 뒤 시스템 프롬프트, 도구 오류 처리, 코드 경로 등 구체적인 수정 지점과 우선순위를 제시한다는 점입니다.
🧠 상세 정리
1. 최종 출력만 보는 에이전트 평가는 충분하지 않다
글은 AI 에이전트를 일반 소프트웨어처럼 최종 출력이 기대와 일치하는지만 확인하는 방식으로 평가하는 관행에서 출발합니다. 하지만 에이전트는 스스로 도구를 선택하고 여러 정보원을 오가며 작업 순서를 구성하므로, 최종 답변만으로는 실제 행동을 충분히 설명할 수 없습니다. 예를 들어 답변은 구조화되어 있고 실행 가능해 보이지만, 도구가 빈 결과를 반환했는데도 사실을 지어낸 것일 수 있습니다. 반대로 결론은 맞더라도 신뢰할 수 있는 과정에 필요한 검증 단계를 건너뛰었을 수도 있습니다. 이런 실패는 최종 응답 표면 아래에 있기 때문에, 어떤 도구를 호출했고 그 도구가 무엇을 반환했으며 답변이 그 데이터와 충실히 연결되는지를 추적해야 포착할 수 있습니다.
2. 필요한 평가는 테스트·관측성·지표를 함께 요구한다
저자들은 이 간극을 메우려면 대부분의 에이전트 개발팀이 처음부터 직접 만들기 어려운 평가 인프라가 필요하다고 설명합니다. 단순한 입출력 테스트가 아니라, 정답 또는 기대 결과가 있는 테스트 케이스가 있어야 하고, 도구 호출과 중간 상태를 기록할 관측성 계측도 필요합니다. 또한 표면적인 정확도만이 아니라 답변이 실제 도구 결과에 근거하는지, 도구 사용이 적절했는지, 사용자에게 유용하고 일관된 답변인지까지 평가하는 지표가 필요합니다. 에이전트 품질은 하나의 점수로 환원되지 않으며, 그럴듯한 문장과 신뢰할 수 있는 실행 과정은 별개의 문제입니다. 따라서 각 품질 차원을 독립적으로 확인하는 평가 체계가 요구됩니다.
3. Agent-EvalKit은 평가 워크플로를 개발 환경 안으로 가져온다
Agent-EvalKit은 Apache 2.0 라이선스의 오픈소스 툴킷으로, Claude Code, Kiro CLI, Kilo Code 같은 AI 코딩 어시스턴트와 통합되어 에이전트 평가 인프라를 제공합니다. 이 도구의 특징은 평가를 배포 후 별도 단계로 분리하지 않고 개발 환경 내부에서 수행하게 한다는 점입니다. 사용자는 자연어로 평가 목표를 설명하고, 툴킷은 에이전트 소스 코드 읽기부터 타깃 테스트 케이스 생성, 평가 실행, 개선 권고가 포함된 보고서 작성까지 이어지는 과정을 지원합니다. 보고서의 권고는 코드베이스의 구체적 위치를 참조하도록 설계되어 있습니다. 즉, 평가 결과가 추상적인 품질 점수에 머무르지 않고 실제 수정 작업으로 이어지도록 구성됩니다.
4. 평가 지표는 응답 품질, 도구 사용, 근거 충실성을 나누어 봐야 한다
글은 무엇을 측정할지 정하는 일도 인프라 구축만큼 어렵다고 강조합니다. 에이전트의 답변이 도구가 실제 반환한 내용에 근거하는지, 올바른 도구를 올바른 파라미터로 호출했는지, 최종 출력이 사용자에게 일관되고 유용한지를 각각 확인해야 하기 때문입니다. 하나의 지표는 이 모든 차원을 충분히 설명하지 못합니다. 코드 기반 평가자는 빠르고 재현 가능하지만 접근 방식의 유효한 변형까지 벌점으로 처리할 수 있습니다. 반면 LLM-as-judge 방식은 더 섬세한 판단을 제공할 수 있지만 추가 추론 비용과 신중한 프롬프트 설계가 필요합니다. 그래서 효과적인 평가는 두 방식을 조합하고, 점수를 코드 변경으로 번역하는 단계까지 포함해야 합니다.
5. AI 코딩 어시스턴트가 평가 엔진 역할을 한다
Agent-EvalKit은 별도의 평가 플랫폼처럼 동작하기보다, 기존 AI 코딩 어시스턴트를 평가 엔진으로 활용합니다. 사용자는 /evalkit.plan, /evalkit.data 같은 슬래시 명령 뒤에 자연어 지시를 덧붙여 어떤 품질 차원을 중점적으로 볼지 알려줍니다. 어시스턴트는 에이전트의 도구 정의, 시스템 프롬프트, 프레임워크 설정을 읽고 에이전트가 무엇을 할 수 있으며 어디서 실패할 수 있는지 모델링합니다. 이후 생성되는 평가 계획, 테스트 데이터, 최종 보고서 같은 산출물은 이 코드 수준 이해를 바탕으로 만들어집니다. 같은 어시스턴트가 개발과 평가를 모두 돕기 때문에, 평가가 개발 흐름과 분리되지 않는다는 점이 핵심입니다.
6. 여섯 단계가 평가 생애주기를 구성한다
Agent-EvalKit의 워크플로는 Plan, Data, Trace, Run agent, Eval, Report의 여섯 단계로 구성됩니다. Plan 단계는 에이전트 코드를 읽어 도구와 프레임워크를 이해하고 각 지표를 구체적인 평가 방법과 연결하는 평가 계획을 만듭니다. Data 단계는 계획에 근거해 입력과 기대 결과가 포함된 테스트 케이스를 만들며, 기존 운영 로그나 수동 테스트 데이터도 사용할 수 있습니다. Trace 단계는 OpenTelemetry 호환 추적을 추가해 실행 경로를 보이게 하고, Run agent 단계는 각 테스트 케이스에 대해 도구 호출, 모델 응답, 중간 상태를 구조화된 trace 파일로 남깁니다. Eval 단계는 계획의 지표를 실행 가능한 평가 코드로 구현해 결과를 저장하고, Report 단계는 패턴을 분석해 코드 위치와 예상 효과가 포함된 우선순위 권고를 생성합니다.
7. 여행 리서치 에이전트 사례는 품질과 신뢰성의 차이를 보여준다
글은 Strands Agents SDK와 Amazon Bedrock으로 만든 여행 리서치 에이전트를 실행 예시로 사용합니다. 이 에이전트는 웹 검색, 항공편 정보, 기후 데이터, 통화 변환, 예산 계산 도구를 사용해 여행 계획을 돕지만, 때때로 지나치게 정밀해 보이는 숫자를 제시하는 문제가 관찰되었습니다. Agent-EvalKit은 Plan 단계에서 Faithfulness, Tool Parameter Accuracy, Response Quality라는 세 가지 지표를 중심으로 평가를 설계했습니다. Data 단계에서는 목적지 조사, 계절별 시기, 일정 구성, 비교 질문, 예산 계산을 포함한 100개의 멀티턴 테스트 세션을 생성했습니다. 이후 단계들은 각 세션을 실행하며 상세한 실행 추적을 수집했고, 문제의 범위와 원인을 지표와 trace로 드러냈습니다.
8. 결과는 빈 도구 응답이 환각으로 이어지는 패턴을 드러냈다
평가 결과는 응답의 겉보기 품질과 실제 신뢰성 사이에 큰 차이가 있음을 보여주었습니다. Response Quality는 83.9%로, 에이전트가 명확하고 실행 가능한 여행 조언을 제공한다는 점을 확인했습니다. Tool Parameter Accuracy는 64.5%로, 대체로 적절한 도구를 고르지만 일부 파라미터가 부정확하다는 사실을 보여주었습니다. 그러나 Faithfulness는 32.3%에 그쳤고, 웹 검색 도구가 빈 결과나 불완전한 결과를 반환할 때 환율, 온도, 명소 세부 정보를 지어내며 그것을 도구에서 얻은 정보처럼 제시한다는 문제가 확인되었습니다. 보고서는 빈 도구 결과를 명시적으로 공개하도록 시스템 프롬프트를 보강하고, 모든 코드 경로에서 도구 오류 처리를 개선하는 것을 최우선 수정 사항으로 제안했습니다.
🧾 핵심 주장 / 시사점
- 에이전트 평가는 최종 답변의 자연스러움이 아니라, 답변이 실제 도구 결과와 어떤 실행 경로를 거쳐 연결되었는지를 검증하는 방향으로 이동해야 합니다.
- Agent-EvalKit의 중요한 차별점은 평가 점수를 만드는 데서 끝나지 않고, 실행 trace와 실패 패턴을 코드 위치 기반 개선 권고로 바꾼다는 점입니다.
- 사례에서 보듯 응답 품질 점수가 높아도 근거 충실성이 낮을 수 있으므로, 에이전트 신뢰성 평가는 품질·도구 사용·근거성을 분리해 측정해야 합니다.
✅ 액션 아이템
- 원문에서 강조한 핵심 변화와 이해관계자를 기준으로 Evaluate AI agents systematically with Agent-EvalKit | Amazon Web Services의 영향을 정리한다.
- 다음 의사결정이나 제품/정책 판단에 연결될 수 있는 근거를 원문 문장과 함께 기록한다.
- 기사에서 제시한 수치·사례·제약 조건을 분리해 과장 없이 검토한다.
- 후속 모니터링이 필요한 발표·제품·정책 변화가 있는지 출처 링크를 기준으로 추적한다.
❓ 열린 질문
- The best open source frameworks for building AI agents in 2026]]" "99. 이 변화가 실제 사용자나 조직의 선택 기준을 어떻게 바꿀까?
- OpenClaw로 15명 AI 팀 운영기 월 400달러 멀티에이전트 시스템" "185. 이 근거가 다른 산업이나 지역에서도 동일하게 적용될 수 있을까?
- Anthropic’s Claude Code creator says there are days he manages tens of thousands of AI agents at once Fortune" "129. 기사에서 아직 검증되지 않은 전제나 리스크는 무엇일까?
- OpenClaw 3.8 IS INSANE Here's Why" "[[220. 후속 발표나 데이터가 나오면 어떤 지표를 먼저 비교해야 할까?





