Build self-service AWS Health analytics to find actionable health insights with AI agents powered by Amazon Bedrock
Quick Summary
이 글은 여러 AWS 계정에 흩어진 AWS Health 이벤트를 Chaplin이라는 오픈소스 MCP 기반 AI 에이전트 시스템으로 수집·분류·분석해 운영팀이 자연어로 즉시 실행 가능한 인사이트를 얻는 방법을 설명합니다.

🖼️ 인포그래픽
🖼️ 4컷 인포그래픽
💡 한 줄 요약
이 글은 여러 AWS 계정에 흩어진 AWS Health 이벤트를 Chaplin이라는 오픈소스 MCP 기반 AI 에이전트 시스템으로 수집·분류·분석해 운영팀이 자연어로 즉시 실행 가능한 인사이트를 얻는 방법을 설명합니다.
📌 핵심 요약
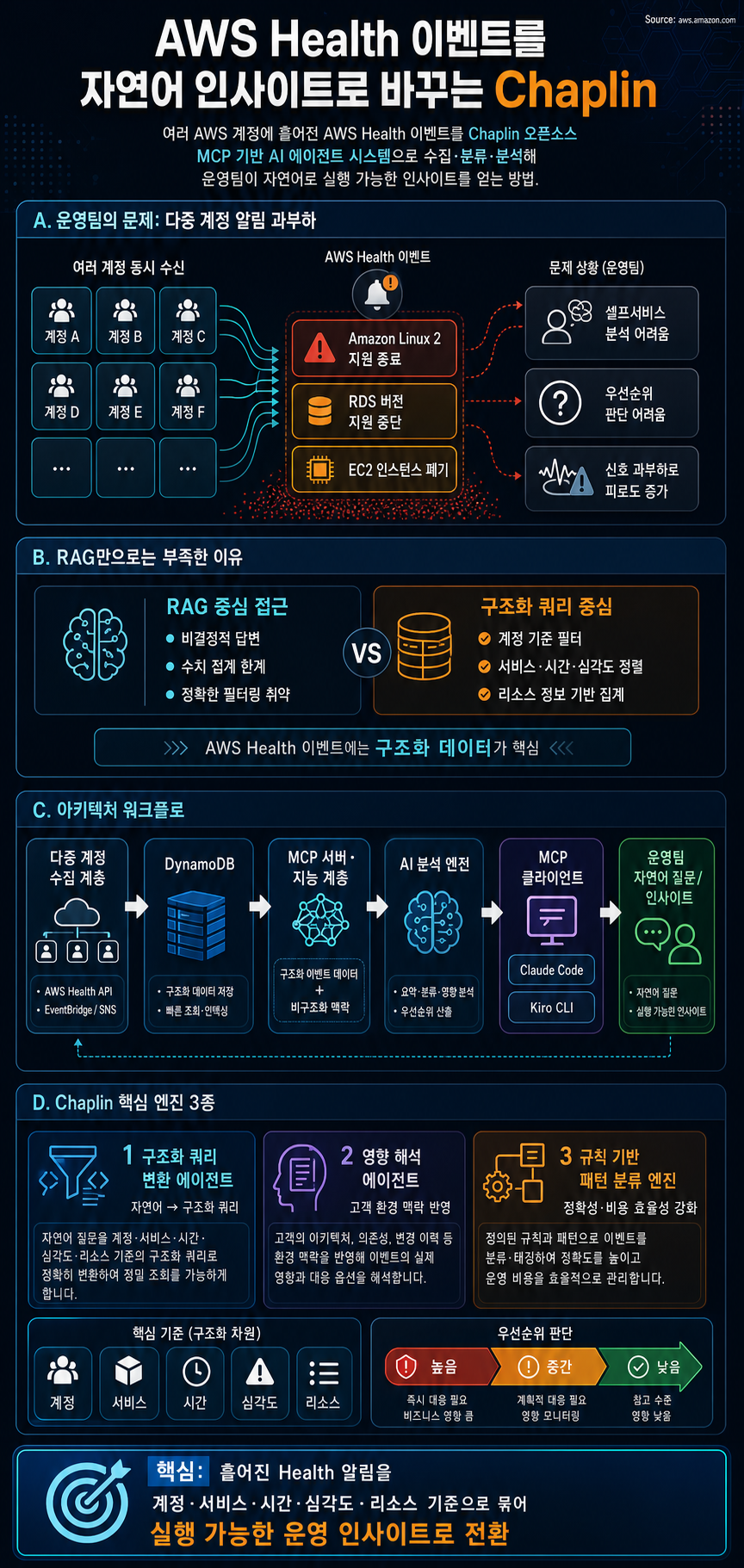
- 기업 운영팀은 Amazon Linux 2 지원 종료, RDS 버전 지원 중단, EC2 인스턴스 폐기 같은 AWS Health 알림을 여러 계정에서 동시에 받지만, 셀프서비스 분석이 없으면 어떤 이벤트가 운영 환경에 영향을 주는지 빠르게 판단하기 어렵습니다.
- Chaplin은 AWS Health 이벤트를 자연어로 질의할 수 있게 하는 오픈소스 솔루션으로, MCP 호환 AI 어시스턴트에서 질문하면 구조화된 이벤트 데이터와 비구조화된 설명을 함께 분석해 맥락화된 답변을 제공합니다.
- 글은 RAG 기반 접근이 수치 집계와 정확한 필터링에서 비결정적 한계를 갖는다고 설명하며, AWS Health 이벤트처럼 계정, 서비스, 시간, 심각도, 리소스 정보가 필요한 데이터에는 구조화된 쿼리와 의미 분석의 결합이 필요하다고 강조합니다.
- Chaplin은 자연어를 구조화 쿼리로 바꾸는 에이전트, 고객 환경 맥락을 반영해 영향을 해석하는 에이전트, 규칙 기반 패턴 분류 엔진을 함께 사용해 정확성과 비용 효율성을 동시에 추구합니다.
- 아키텍처는 다중 계정 수집 계층, DynamoDB와 AI 분석 엔진이 있는 MCP 서버·지능 계층, Claude Code나 Kiro CLI 같은 MCP 클라이언트 프레젠테이션 계층으로 구성되며, 팀은 기존 개발 환경에서 자연어로 이벤트 분석을 수행할 수 있습니다.
🧩 주요 포인트
- 기업 운영팀은 Amazon Linux 2 지원 종료, RDS 버전 지원 중단, EC2 인스턴스 폐기 같은 AWS Health 알림을 여러 계정에서 동시에 받지만, 셀프서비스 분석이 없으면 어떤 이벤트가 운영 환경에 영향을 주는지 빠르게 판단하기 어렵습니다.
- Chaplin은 AWS Health 이벤트를 자연어로 질의할 수 있게 하는 오픈소스 솔루션으로, MCP 호환 AI 어시스턴트에서 질문하면 구조화된 이벤트 데이터와 비구조화된 설명을 함께 분석해 맥락화된 답변을 제공합니다.
- 글은 RAG 기반 접근이 수치 집계와 정확한 필터링에서 비결정적 한계를 갖는다고 설명하며, AWS Health 이벤트처럼 계정, 서비스, 시간, 심각도, 리소스 정보가 필요한 데이터에는 구조화된 쿼리와 의미 분석의 결합이 필요하다고 강조합니다.
- Chaplin은 자연어를 구조화 쿼리로 바꾸는 에이전트, 고객 환경 맥락을 반영해 영향을 해석하는 에이전트, 규칙 기반 패턴 분류 엔진을 함께 사용해 정확성과 비용 효율성을 동시에 추구합니다.
- 아키텍처는 다중 계정 수집 계층, DynamoDB와 AI 분석 엔진이 있는 MCP 서버·지능 계층, Claude Code나 Kiro CLI 같은 MCP 클라이언트 프레젠테이션 계층으로 구성되며, 팀은 기존 개발 환경에서 자연어로 이벤트 분석을 수행할 수 있습니다.
🧠 상세 정리
1. 운영팀이 마주하는 AWS Health 이벤트의 복잡성
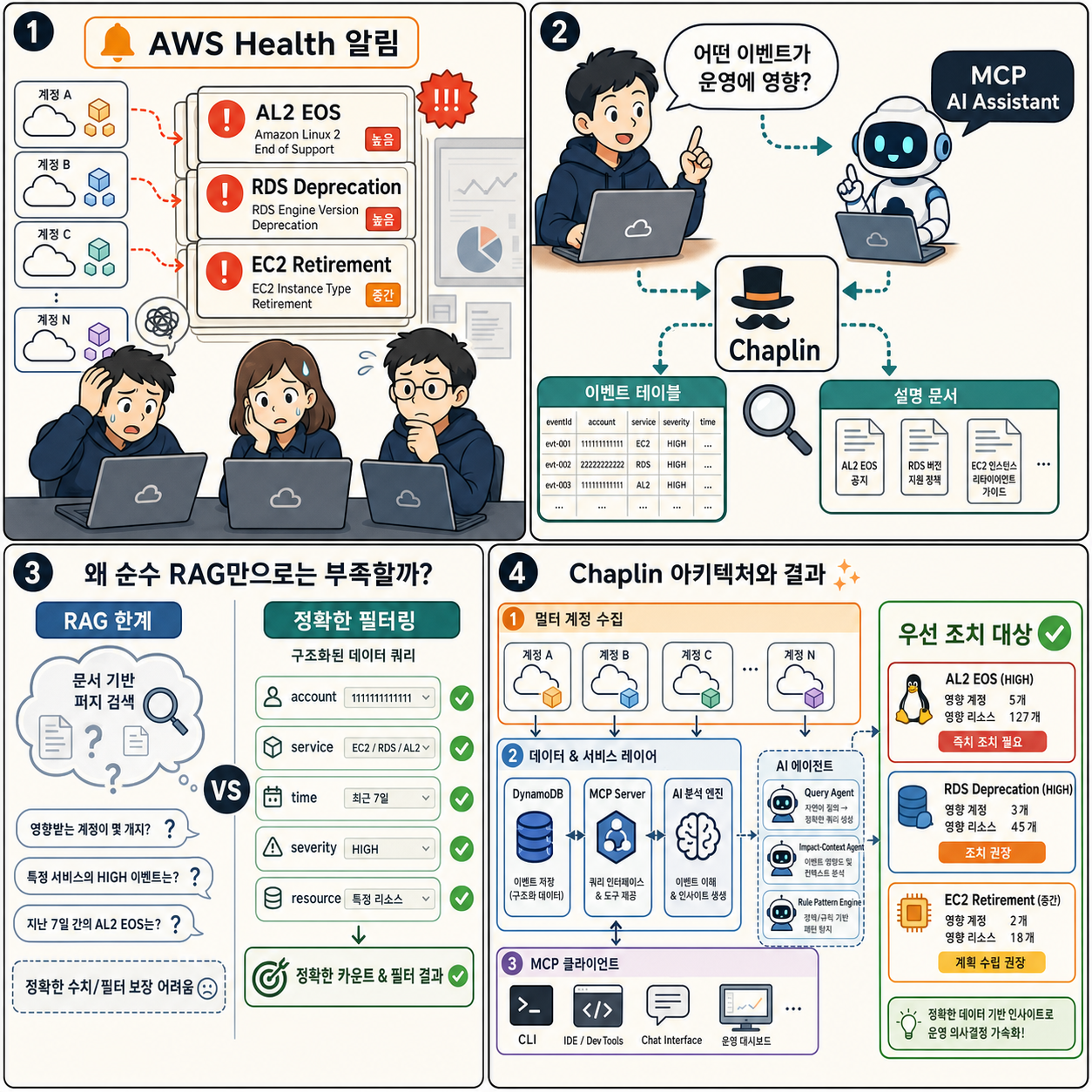
글은 월요일 아침 한 운영팀이 50개가 넘는 계정에서 Amazon Linux 2 지원 종료, RDS 버전 지원 중단, EC2 인스턴스 폐기 같은 여러 AWS Health 알림을 받는 상황으로 문제를 제시합니다. 이런 이벤트는 단순 알림이 아니라 운영 환경, 장기 계획, 즉시 대응 여부, 비즈니스 영향 판단과 연결됩니다. 하지만 셀프서비스 분석 체계가 없으면 어떤 이벤트가 프로덕션 시스템에 영향을 주는지, 어떤 항목을 우선 처리해야 하는지, 어떤 이벤트가 장기 마이그레이션 계획에 속하는지 빠르게 구분하기 어렵습니다. 그 결과 운영팀은 능동적인 개선보다 사후 대응과 긴급 소방에 시간을 쓰게 됩니다.
2. TAM 의존과 기존 대시보드 방식의 한계
원문은 운영팀이 Health 이벤트 해석과 영향 분석을 위해 Technical Account Manager에게 의존하는 구조가 의사결정 병목을 만든다고 설명합니다. AWS Health API와 Amazon EventBridge는 포괄적인 이벤트 데이터를 제공하지만, 데이터가 존재한다는 사실만으로 운영 판단이 자동으로 이루어지지는 않습니다. 사전에 정의된 스키마를 가진 비즈니스 인텔리전스 대시보드는 정해진 질문에는 답할 수 있어도, 그때그때 달라지는 운영팀의 동적 질문이나 맥락적 판단에는 유연하게 대응하기 어렵습니다. 특히 여러 계정과 리전에 흩어진 수천 개 이벤트를 수동으로 분류하고 우선순위를 매기는 과정은 전체 영향 평가와 팀 간 대응 조율을 어렵게 만듭니다.
3. Chaplin의 목표와 자연어 기반 셀프서비스 분석
Chaplin은 Customer Health and Planned Lifecycle Intelligence Nexus의 약자로, MCP를 통해 노출되는 AI 에이전트를 사용해 AWS Health 이벤트를 셀프서비스 방식으로 분석하는 오픈소스 솔루션입니다. 사용자는 별도 맞춤 프런트엔드가 아니라 Claude Code나 Kiro CLI 같은 MCP 호환 AI 어시스턴트에서 자연어로 질문할 수 있습니다. 예를 들어 다음 60일 동안 예정된 RDS 라이프사이클 이벤트, 긴급도 기준으로 정렬된 열린 EC2 이벤트, 프로덕션 환경에 영향을 주는 보안 패치, 고우선순위 애플리케이션에 영향을 줄 수 있는 유지보수 기간 등을 물을 수 있습니다. 이 방식은 AWS Support에 일상 분석을 의존하지 않고 운영·보안·DevOps 팀이 스스로 필요한 정보를 반복 질의하며 대응 계획을 세우도록 돕습니다.
4. MCP가 제공하는 워크플로 통합과 비즈니스 맥락 연결
원문은 Chaplin이 MCP를 사용하기 때문에 팀이 Health 이벤트 분석을 기존 AI 어시스턴트 기반 작업 흐름 안에서 수행할 수 있다고 설명합니다. 또한 JIRA, GitHub, ServiceNow 같은 다른 MCP 지원 도구와 결합하면 분석 결과를 기반으로 후속 조치를 수행하는 에이전트 경험으로 확장할 수 있습니다. MCP는 AWS 데이터와 메타데이터를 리소스 태그, 환경 분류, 소유자 정보, 애플리케이션 수준 맥락 같은 조직 내부 정보와 직접 연결하는 역할도 합니다. 이 연결 덕분에 같은 이벤트라도 단순히 ‘발생했다’는 사실을 넘어서, 특정 조직의 운영 환경에서 어떤 의미를 가지는지까지 분석할 수 있습니다.
5. 구조화 데이터와 비구조화 데이터를 함께 다뤄야 하는 이유
글은 AWS Health 이벤트 분석의 핵심 난점이 구조화 데이터와 비구조화 데이터를 함께 처리해야 한다는 점에 있다고 설명합니다. 이벤트에는 이벤트 유형, 서비스 이름, 영향받는 리소스, 타임스탬프, 심각도, 계정 ID처럼 정확한 필터링과 집계가 필요한 구조화 메타데이터가 포함됩니다. 동시에 이벤트 설명에는 문제의 의미, 영향 평가, 권장 조치 같은 자연어 설명이 들어 있어 의미 이해와 맥락 분석이 필요합니다. 원문은 전통적인 RAG나 생성형 AI 접근이 벡터 유사도 검색과 확률적 생성에 의존하기 때문에 수치 계산과 집계에서 정확성을 보장하지 못할 수 있다고 지적하며, Health 이벤트 분석에는 정확한 쿼리와 의미 분석의 분리가 필요하다고 봅니다.
6. 세 가지 지능형 처리 구성요소
Chaplin에서 사용자가 질문하면 세 가지 전문 구성요소가 함께 작동합니다. 자연어-구조화 쿼리 에이전트는 event_type, affected_accounts, start_time 같은 Health 이벤트 스키마를 이해하고, 평문 질문을 정확한 필드 필터가 있는 구조화 쿼리로 바꿉니다. 맥락적 영향 분석 에이전트는 이벤트의 비구조화 설명을 고객 메타데이터와 결합해 프로덕션 여부, 비프로덕션 여부, 비즈니스 유닛, 애플리케이션 계층, 소유 정보 같은 조직 맥락에서 해석합니다. 패턴 기반 분류 엔진은 규칙 기반 패턴 매칭으로 일상적인 이벤트를 분류해 대부분의 반복 처리에서 AI 비용을 줄이면서 높은 정확도를 유지하는 역할을 합니다.
7. 비용 최적화를 고려한 AI 아키텍처
원문은 Chaplin이 선택적 AI 보강 방식을 통해 비용 최적화를 구현한다고 설명합니다. 먼저 규칙 기반 분류가 대부분의 이벤트를 처리하고, 맥락 분석이 필요한 비구조화 데이터에만 AI 처리를 적용하는 구조입니다. 30일, 60일, 120일 창에 대한 사전 요약 뷰와 필터는 팀이 중요한 알림을 빠르게 찾도록 돕습니다. 현재 구현에서는 Amazon Bedrock과 Claude가 맥락 분석이 필요한 비구조화 데이터를 처리하지만, 솔루션 자체는 특정 모델 제공자에 고정되지 않고 OpenAI, Anthropic, Ollama 같은 다른 모델도 사용할 수 있도록 설명됩니다. 또한 캐싱과 AWS Health API 스키마 기반의 정확한 구조화 쿼리를 통해 불필요한 AI 추론 비용을 줄입니다.
8. 다중 계정 수집부터 MCP 클라이언트까지의 아키텍처
Chaplin 아키텍처는 크게 데이터 계층, 중간 계층, 프레젠테이션 계층으로 설명됩니다. 데이터 계층에서는 각 멤버 계정의 AWS Health API가 이벤트 소스가 되고, Amazon EventBridge와 AWS Lambda 수집 함수가 교차 계정 IAM 역할을 통해 이벤트를 가져와 중앙 관리 계정으로 보냅니다. 중앙에서는 Amazon S3 데이터 레이크가 계정, 날짜, 이벤트 유형 기준으로 이벤트를 저장하고, S3 이벤트 알림이 Lambda를 트리거해 JSON Health 이벤트를 DynamoDB에 적재합니다. 중간 계층에서는 DynamoDB, 패턴 기반 분류기, Amazon Bedrock 기반 분석 엔진, Strands Agents 프레임워크와 여러 전문 에이전트가 MCP 도구로 기능을 노출합니다. 마지막 프레젠테이션 계층에서는 Claude Code나 Kiro CLI 같은 MCP 호환 AI 어시스턴트가 이 도구를 호출해 사용자의 자연어 질문에 대한 맥락화된 결과를 대화형으로 제공합니다.
🧾 핵심 주장 / 시사점
- 핵심 전환점은 Health 이벤트를 ‘알림 목록’이 아니라 운영 의사결정을 위한 질의 가능한 데이터 자산으로 보는 데 있습니다.
- 정확한 집계가 필요한 구조화 데이터와 맥락 해석이 필요한 비구조화 설명을 분리해 처리하는 설계가 RAG 단독 접근의 한계를 보완합니다.
- MCP 기반 접근은 별도 대시보드를 만드는 대신 기존 AI 어시스턴트와 운영 도구 흐름 안에서 분석과 후속 조치를 연결하려는 방향을 보여줍니다.
✅ 액션 아이템
- 다중 계정 AWS Health 알림을 통합 수집해 계정별 이벤트 목록의 중복·누락 없이 현재 영향도를 빠르게 판단한다.
- 자연어 질의 파이프라인에서 구조화 쿼리 변환 단계를 두어 계정·서비스·시간·심각도 기준 필터링 정확도를 높인다.
- 규칙 기반 패턴 분류와 고객 환경 맥락 해석 에이전트를 함께 운용해 실행 가능한 인사이트만 신속히 반환한다.
❓ 열린 질문
- RAG 단독 대비 구조화 쿼리 결합 시 필터 정확도 개선 폭을 어떤 지표로 판단할 것인가?
- AWS Health 이벤트 처리에서 MCP 수집 계층·AI 분석 계층의 비용 부담을 어디까지 분리할 것인가?
- 자연어 질문 응답의 오답 제안을 억제하기 위해 어떤 실패 패턴을 선제적으로 제외할 것인가?





