Build an AI-Powered Equipment Repair Assistant Using Amazon Bedrock AgentCore
Quick Summary
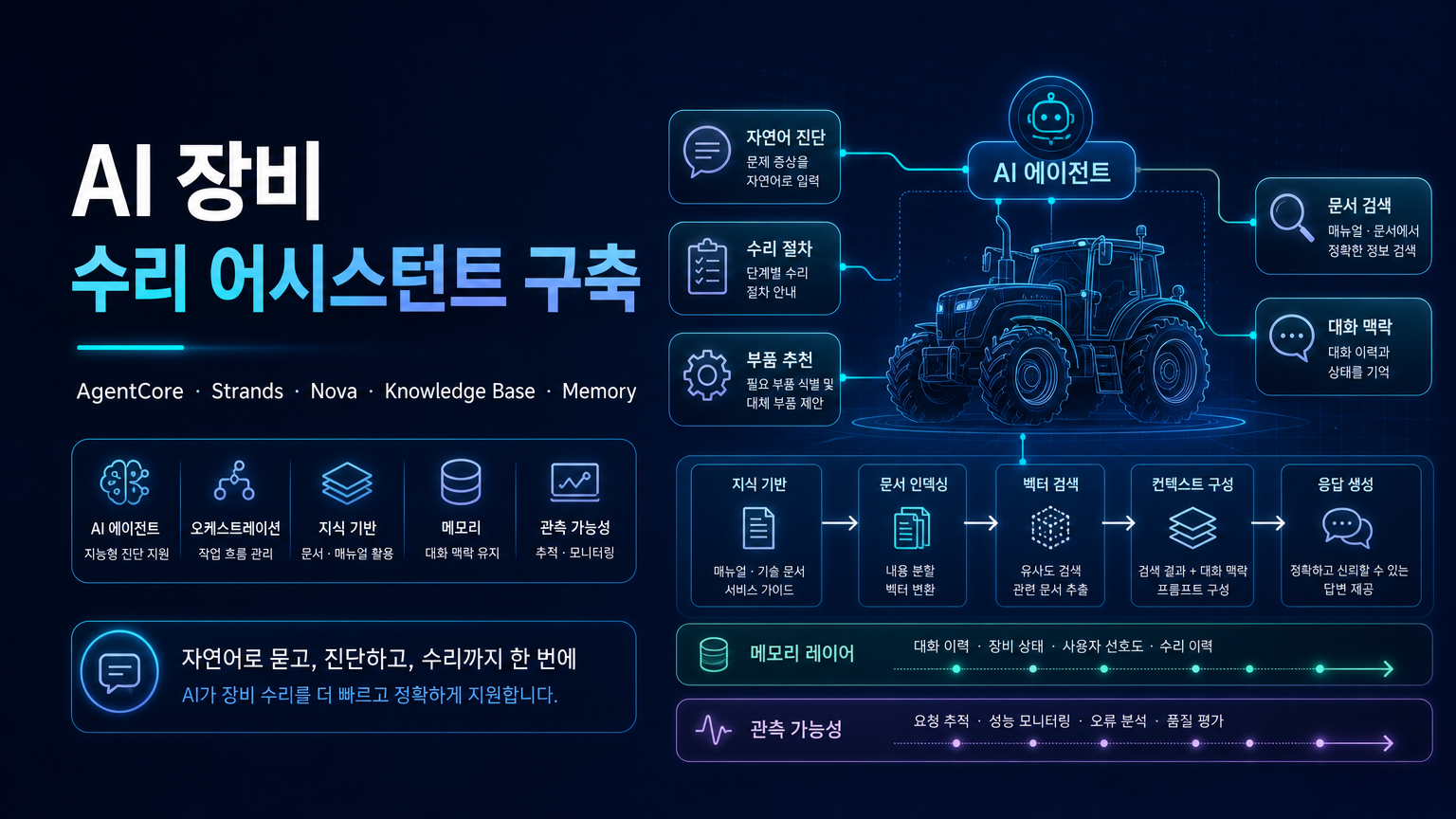
AWS는 Amazon Bedrock AgentCore, Strands Agents SDK, Amazon Nova 2 Lite, Bedrock Knowledge Base, AgentCore Memory를 결합해 농기계 수리 현장에서 자연어로 고장 진단과 부품·절차 추천을 제공하는 AI 장비 수리 assistant 아키텍처를 제시했다.
🖼️ 인포그래픽

🖼️ 4컷 인포그래픽

📰 Build an AI-Powered Equipment Repair Assistant Using Amazon Bedrock AgentCore | Amazon Web Services
💡 한 줄 요약
AWS는 Amazon Bedrock AgentCore, Strands Agents SDK, Amazon Nova 2 Lite, Bedrock Knowledge Base, AgentCore Memory를 결합해 농기계 수리 현장에서 자연어로 고장 진단과 부품·절차 추천을 제공하는 AI 장비 수리 assistant 아키텍처를 제시했다.
📌 핵심 요약
- 이 글은 농기계 수리 현장의 반복 방문, 부품 부족, 긴 다운타임 문제를 AI agent 기반 진단 assistant로 줄이는 예제를 설명한다.
- 핵심 런타임은 Amazon Bedrock AgentCore이며, agent는 AgentCore Runtime 위에서 Strands Agents SDK로 구현된다.
- 모델은 Amazon Nova 2 Lite를 사용하고, 제조사 매뉴얼·부품 카탈로그·수리 문서는 Amazon Bedrock Knowledge Base와 Amazon OpenSearch Serverless를 통해 검색된다.
- 사용자 인증과 웹 프론트엔드는 Amazon Cognito와 AWS Amplify가 맡고, 대화 맥락은 AgentCore Memory가 단기·장기 메모리로 유지한다.
- AWS는 이 구조가 평균 수리 시간 단축, 첫 방문 수리 성공률 개선, 단일 AgentCore endpoint 운영, CloudWatch/X-Ray observability, 도구 확장성을 제공한다고 설명한다.
🧩 주요 포인트
- 문제의 출발점은 현장 기술자가 정확한 부품이나 절차 없이 장비 문제를 진단해야 해서 여러 번 현장을 방문하고, 특히 수확기 같은 시기에 큰 다운타임 비용이 발생한다는 점이다.
- 솔루션은 field technician이나 farmer가 자연어로 장비 증상을 묻고, agent가 제조사 승인 문서와 부품 정보를 바탕으로 진단·수리 절차·부품 추천을 제공하도록 설계된다.
- AgentCore Runtime은 Strands 기반 agent를 호스팅하고
/invocationsendpoint를 노출한다. 프론트엔드는 Cognito Bearer token으로 이 endpoint를 호출한다. - agent는
search_equipment_knowledgetool을 통해 Bedrock Knowledge Base의retrieve_and_generateAPI를 호출하고, Knowledge Base는 S3에 저장된 문서를 Amazon OpenSearch Serverless와 Amazon Titan Embeddings로 색인한다. - AgentCore Memory는 한 진단 세션 안의 단기 맥락과 여러 세션에 걸친 장기 지식을 유지해, 사용자가 같은 정보를 반복 입력하지 않게 한다.
- 운영 측면에서는 CloudWatch와 AWS X-Ray가 tracing과 observability를 제공하고, Amazon DynamoDB는 장비 service ticket/issue CRUD 데이터를 저장한다.
🧠 상세 정리
1. 현장 수리 문제를 agent 문제로 바꾼다
원문은 농기계 field service의 병목을 “정보 부족”과 “반복 방문”으로 정의한다. 기술자가 현장에 도착했을 때 필요한 부품이나 제조사 절차를 바로 확인하지 못하면 진단과 수리가 분리되고, 이 과정에서 장비 다운타임이 길어진다. AWS 예제는 이 문제를 AI-powered equipment repair assistant로 풀려고 한다. 사용자는 John Deere 1023E/1025R 같은 장비 증상, 예를 들어 hydraulic pressure가 특정 조건에서 떨어지는 문제를 자연어로 입력하고, assistant는 관련 문서와 수리 절차를 찾아 답한다.
2. AgentCore Runtime과 Strands Agents SDK가 agent 실행 계층을 맡는다
아키텍처의 중심은 Amazon Bedrock AgentCore다. agent는 AgentCore Runtime에 배포되고, 구현은 Strands Agents SDK를 사용한다. 런타임은 /invocations endpoint를 제공하며, 프론트엔드는 이 endpoint에 사용자의 질문을 보낸다. agent의 invoke() entrypoint는 payload의 path에 따라 /chat 요청과 /issues CRUD 요청을 내부적으로 라우팅한다. 이 구조는 별도의 API Gateway, Lambda, Bedrock Agent 리소스를 조합하는 대신 단일 AgentCore endpoint로 agent backend를 운영하는 방향을 보여준다.
3. Knowledge Base와 Amazon Nova 2 Lite가 진단 응답을 만든다
agent의 지식 원천은 Amazon Bedrock Knowledge Base다. 사용자는 장비 매뉴얼, 부품 카탈로그, 수리 문서를 S3에 업로드하고 Knowledge Base를 생성한다. Knowledge Base는 Amazon OpenSearch Serverless vector store와 Amazon Titan Embeddings를 사용해 문서를 색인한다. agent는 search_equipment_knowledge tool을 호출하고, 이 tool은 retrieve_and_generate API로 관련 문서를 검색한다. foundation model은 Amazon Nova 2 Lite이며, 모델은 검색된 문서와 source citation을 바탕으로 진단 답변, 수리 절차, 필요한 부품을 합성한다.
4. Cognito, Amplify, DynamoDB, CloudWatch가 운영 구성을 완성한다
웹 사용자 인증은 Amazon Cognito가 맡고, React frontend는 AWS Amplify로 배포된다. 사용자는 Cognito로 로그인하고, 프론트엔드는 Cognito token을 AgentCore Runtime endpoint에 전달한다. 서비스 티켓과 issue CRUD 데이터는 Amazon DynamoDB에 저장된다. 관측성은 Amazon CloudWatch와 AWS X-Ray가 담당한다. 이 조합은 field service agent를 단순 데모가 아니라 인증, persistence, logging, tracing까지 갖춘 운영 구조로 묶는다.
5. AgentCore Memory는 진단 대화의 연속성을 만든다
수리 현장의 질문은 한 번의 Q&A로 끝나지 않는다. 원문은 AgentCore Memory를 통해 세션 안의 단기 memory와 세션을 넘는 장기 memory를 모두 유지할 수 있다고 설명한다. 예를 들어 기술자가 같은 장비, 같은 증상, 같은 현장 조건을 여러 차례 설명하지 않아도 이전 대화의 맥락을 유지할 수 있다. 장기 memory는 technician specialization, farmer fleet details, 반복되는 issue pattern 같은 정보를 유지하는 데 쓰일 수 있다.
6. 확장성은 새 tool 추가로 열린다
원문은 parts ordering, dealer communication, IoT telemetry 같은 기능을 추가할 수 있다고 제안한다. 핵심은 Strands Agent의 @tool decorator pattern이다. 새로운 기능은 새 tool function을 추가하는 방식으로 확장되며, 원문은 별도의 인프라 변경 없이 inventory check, parts ordering, authorized dealer notification 같은 기능을 붙일 수 있다고 설명한다. 이는 enterprise agent에서 “도구 추가가 곧 업무 범위 확장”이 되는 구조를 잘 보여준다.
7. production 전환에는 안전·보안·비용 관리가 필요하다
원문은 테스트 비용 예시도 제시한다. Amazon Nova 2 Lite model invocation, Bedrock Knowledge Base의 OpenSearch Serverless 비용, 그리고 DynamoDB/S3/Amplify/Cognito 같은 주변 서비스 비용을 고려해야 한다. 또한 모든 리소스는 같은 AWS Region에 배포해야 하며, production에서는 Amazon Bedrock Guardrails, CloudFront와 AWS WAF, Cognito MFA, CloudWatch alarm, Bedrock model invocation logging, S3 lifecycle policy, DynamoDB point-in-time recovery, multi-region deployment가 고려사항으로 제시된다. 특히 실제 장비 수리 추천은 warranty와 safety guideline을 지켜야 하며, 고압 유압·전기·회전 기계 같은 위험을 명확히 경고해야 한다.
🧾 핵심 주장 / 시사점
- AgentCore는 단순 챗봇이 아니라 인증, 런타임, tool 호출, Knowledge Base, memory, observability를 묶어 현장 업무형 agent를 운영 가능한 형태로 만들려는 AWS의 agent platform 전략이다.
- field service나 제조·농업처럼 문서 기반 절차와 현장 판단이 섞인 영역은 RAG + agent memory + tool orchestration이 실질적 가치를 만들 수 있는 대표적 적용처다.
- enterprise agent의 품질은 모델 성능만으로 결정되지 않는다. Cognito 인증, Knowledge Base 품질, OpenSearch indexing, AgentCore Memory 설계, CloudWatch/X-Ray observability, safety guardrail이 함께 맞아야 한다.
- AYC 관점에서는 “agent가 실제 업무 시스템의 endpoint가 되는 구조”를 설명하기 좋은 사례다. 특히 AgentCore Runtime과 Bedrock Knowledge Base를 중심으로 agent가 어떻게 운영 서비스가 되는지 보여준다.
✅ 액션 아이템
- Amazon Bedrock의 에이전트 실행 계층을 단순 챗봇 호스팅이 아니라 enterprise 업무 endpoint로 볼 수 있는지 검토한다.
- AWS 런타임 endpoint와 Strands Agents SDK 조합이 기존 API Gateway/Lambda/Bedrock Agent 조합과 비교해 어떤 운영 단순화를 주는지 정리한다.
- Amazon Bedrock Knowledge Base, Amazon Nova 2 Lite, Amazon OpenSearch Serverless를 묶은 RAG 구조가 field service 외 다른 산업 문서 업무에도 적용 가능한지 비교한다.
- Amazon Cognito와 AWS Amplify 기반 인증/프론트엔드 구성이 agent 서비스의 사용자 경험과 보안 모델에 어떤 영향을 주는지 확인한다.
- 단기 session memory와 장기 user/fleet memory를 나눌 때 privacy, audit, data lifecycle 요구사항을 함께 점검한다.
❓ 열린 질문
- 장기 memory에 저장되는 technician/fleet context는 어떤 기준으로 보존되어야 하며, 사용자가 삭제나 수정 권한을 가져야 하는 범위는 어디까지인가?
- Amazon Bedrock Knowledge Base가 잘못된 매뉴얼이나 오래된 부품 정보를 검색했을 때, AWS의 에이전트 실행 계층은 어떤 safety guardrail과 source citation으로 오답 수리를 막을 수 있을까?
- Amazon Cognito token을 사용하는 직접 frontend-to-runtime 호출 구조는 내부 업무 앱에서는 충분한가, 아니면 CloudFront/WAF/API proxy가 필요한가?
- Amazon Nova 2 Lite 대신 더 강한 모델을 쓰면 진단 품질은 얼마나 좋아지고, 비용과 latency는 어느 수준까지 허용 가능한가?
- OpenSearch Serverless vector store와 Knowledge Base 동기화 주기를 어떻게 잡아야 제조사 문서 업데이트와 현장 safety requirement를 놓치지 않을 수 있을까?





